The VELaSSCo Platform
Nowadays we can run very large simulations using HPC infrastructures in clusters with distributed computation nodes
The data generated in the simulation sover is componsed of the Mesh and the results of the Mesh for each time step (thousands). Each time step weights typically several Gb, which means actually a huge amount of data (hundreds of Terabytes for big simulations). Nowadays this data provided by the solver in HPC cannot be stored in one single machine, so it is mandatory to apply distributed post-processing and distributed visualization techniques.
Check the overview presentation of the VELaSSCo platform and the project objectives for more details.
The main objective of VELaSSCo project is to build the VELaSSCo Platform, a system that performs distributed post-processing operations and visualization of very large simulations. To reach this goal we will tap into recent advances of Big Data field, which is still unexplored in simulation.
To address this objective, VELaSSCo brings together Simulation and Big Data in a robust and fast platform that allows us to access extremely large amounts of distributed data from very complex virtual models with structured and closely linked data and from measured heterogeneous and loosely coupled data.
It’s important to remark that the advances in the use of well-established and common Big Data technologies (basically based on Hadoop) for the VELaSSCo platform will simplify the adoption by the simulation engineers of these Big Data technologies, and extends the Big Data market by including the CAE domain, what can be considered an important output of the project.
The design of the VELaSSCo Platform has to account for several engineering challenges:
- User requirements and assessment: demand for real-time visualization, fast interactivity and interoperability, realistic visualizations, and so on. (WP1, WP5)
- Simulation data characteristics: very big set of structured and tightly coupled data, highly distributed, possibility to access the data during ongoing simulation, and so on. (WP1)
To address these two challenges, VELaSSCo uses the following set of strategies:
- Take advantage of Big Data technology (in a broad sense, architecture, methods, philosophy…), to perform the post-processing operations faster and in a distributed way. As Big Data works with highly scalable parallel systems, the post-processing algorithms should be programmed to fit these characteristics (WP2, WP3).
- Take advantage of the Big Data properties to pre-compute and store some of the more expensive post-processing operations. Due to the amount of storage facilities the Big Data can manage efficiently, some of the common post-processing operations can be precomputed before the user demands them (WP3).
- Reduce and simplify the data to be visualized, in order to reduce the time for sending the information to the client. Although the results of a simulation may be onto a volume mesh, the user may want to visualize datasets in surface or line meshes (like iso-surfaces or streamlines). This aspect already reduces drastically the information to be sent to the visualization client. Furthermore, novel mesh simplification algorithms are studied in the project to simplify these meshes. Also, the use of B-Splines is studied to represent in a more compact way the sets of results, reducing even more the data size (WP3, WP4).
- Use new GPU-based algorithms and formats to achieve interactive visualization rates in the visualization client.
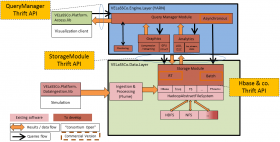
VELaSSCo aims at developing a new concept of integrated end-user visual analysis methods with advanced management and post-processing algorithms for engineering modelling applications, scalable for real-time petabyte level simulations.The Open Source version of the VELaSSCo architecture can be seen below:
The VELaSSCo architecture is composed of different layers (two outside and two inside the platform). The two external layers are in charge of the communication with external components: the HPC nodes, where simulations are running, and the visualization client. For the visualization process, the strategy consists in sending queries to the platform and retrieves the information stored and produced by the platform. The two other layers include different modules dedicated to specific tasks such as to store data, to provide an access point for the data, to compute results on the dataset, etc.
More information about the VELaSSCo Platform can be found in deliverable D3.1. and in general in the WP3 deliverables.
The latest version of the source code of the VELaSSCo platform can be found in the VELaSSCo GitHub site.